En un sistema operativo moderno, es habitual que se ejecuten decenas o cientos de procesos de manera aparentemente simultánea. Sin embargo, cada núcleo de CPU solo puede dedicarse a un proceso a la vez.
Para administrar adecuadamente el tiempo de CPU y decidir qué proceso se ejecuta en cada momento, el sistema operativo hace uso de un planificador (conocido en inglés como scheduler). El planificador selecciona el próximo proceso a ejecutar basándose en los criterios definidos por distintos algoritmos de planificación.
Antes de la era de los sistemas multitarea (capaces de ejecutar múltiples procesos en paralelo de forma concurrida), los sistemas monotarea simplemente ejecutaban una tarea y hasta que esta finalizaba, no se atendía otra. Actualmente, esta dinámica es mucho más compleja, pues intervienen prioridades, tiempos de ejecución, tiempos de espera y otros factores que se almacenan en el PCB (Process Control Block o Bloque de Control de Proceso). Por ello, resulta fundamental comprender cómo se diseña y cómo funciona la planificación de procesos.
5.1 Criterios que determinan un buen algoritmo de planificación
Para evaluar la eficacia de un algoritmo de planificación, se suelen tener en cuenta varios criterios:
Equitatividad (Fairness): Garantizar que todos los procesos reciban una parte justa del tiempo de CPU.
Eficiencia: Pretende mantener la CPU ocupada la mayor parte del tiempo para maximizar el rendimiento del sistema.
Tiempo de Respuesta (Response Time): Reducir al mínimo el tiempo que tarda el sistema en responder a una solicitud de un proceso o de un usuario.
Tiempo de Retorno (Turnaround Time): Disminuir el intervalo que transcurre desde que un proceso entra al sistema hasta que finaliza su ejecución.
Volumen de Producción (Throughput): Maximizar la cantidad de procesos completados en un intervalo de tiempo determinado.
Estos criterios suelen combinarse y priorizarse de forma distinta según el tipo de sistema (por ejemplo, sistemas en tiempo real, sistemas interactivos, servidores de alto rendimiento, etc.).
5.1.1 Conceptos clave en la planificación de procesos
Quantum
El quantum (también llamado time slice) es un intervalo de tiempo fijo que se asigna a un proceso cuando le llega su turno de ejecución. En cuanto se agota este intervalo, el proceso se interrumpe y, si aún no ha terminado, se reubica al final de la cola de listos para esperar un próximo turno. Este mecanismo es fundamental en algoritmos como Round Robin, que busca compartir la CPU de manera equitativa.
Tiempo de espera
El tiempo de espera es el tiempo total que un proceso permanece en la cola de listos antes de poder usar la CPU. Un algoritmo de planificación intenta, en lo posible, minimizar este valor para evitar que los procesos estén inactivos durante demasiado tiempo.
Tiempo de servicio Es el tiempo que la CPU dedica efectivamente a ejecutar un proceso, sin contar los tiempos de espera.
Tiempo de retorno
El tiempo de retorno es el tiempo total que transcurre desde que un proceso entra al sistema (se crea o se pone en la cola de listos) hasta que finaliza su ejecución por completo.
5.2 Algoritmos de planificación de procesos
Existen numerosos algoritmos de planificación que buscan satisfacer uno o varios de los criterios mencionados. A continuación, se presentan tres de los más conocidos y utilizados en entornos académicos y prácticos.
5.2.0.1 Algoritmo Round Robin
Es uno de los más antiguos, sencillos y más utilizados en la planificación de procesos. El algoritmo Round Robin se caracteriza por:
Usar un quantum (por ejemplo, 100 ms).
Repartir la CPU entre los procesos en la cola de manera circular.
Después de que un proceso utiliza la CPU durante un quantum, si no ha terminado, pasa al final de la cola de listos.
Este enfoque favorece la equitatividad, pues cada proceso recibe un turno de ejecución frecuente, evitando que algunos procesos monopolicen la CPU. Sin embargo, si el quantum es muy grande, el comportamiento puede parecerse a FIFO y aumentar el tiempo de espera de otros procesos.
Características del Round Robin (RR)
Política apropiativa: Si el proceso no termina dentro de su quatum de tiempo, se interrumpe y se coloca al final de la cola de procesos listos.
Quantum fijo: Todos los procesos reciben la misma cantidad de tiempo para ejecutarse en cada ciclo.
Cola circular de procesos listos: Los procesos se ejecutan en orden y si no terminan, se colocan nuevamente al final de la cola en espera de terminar.
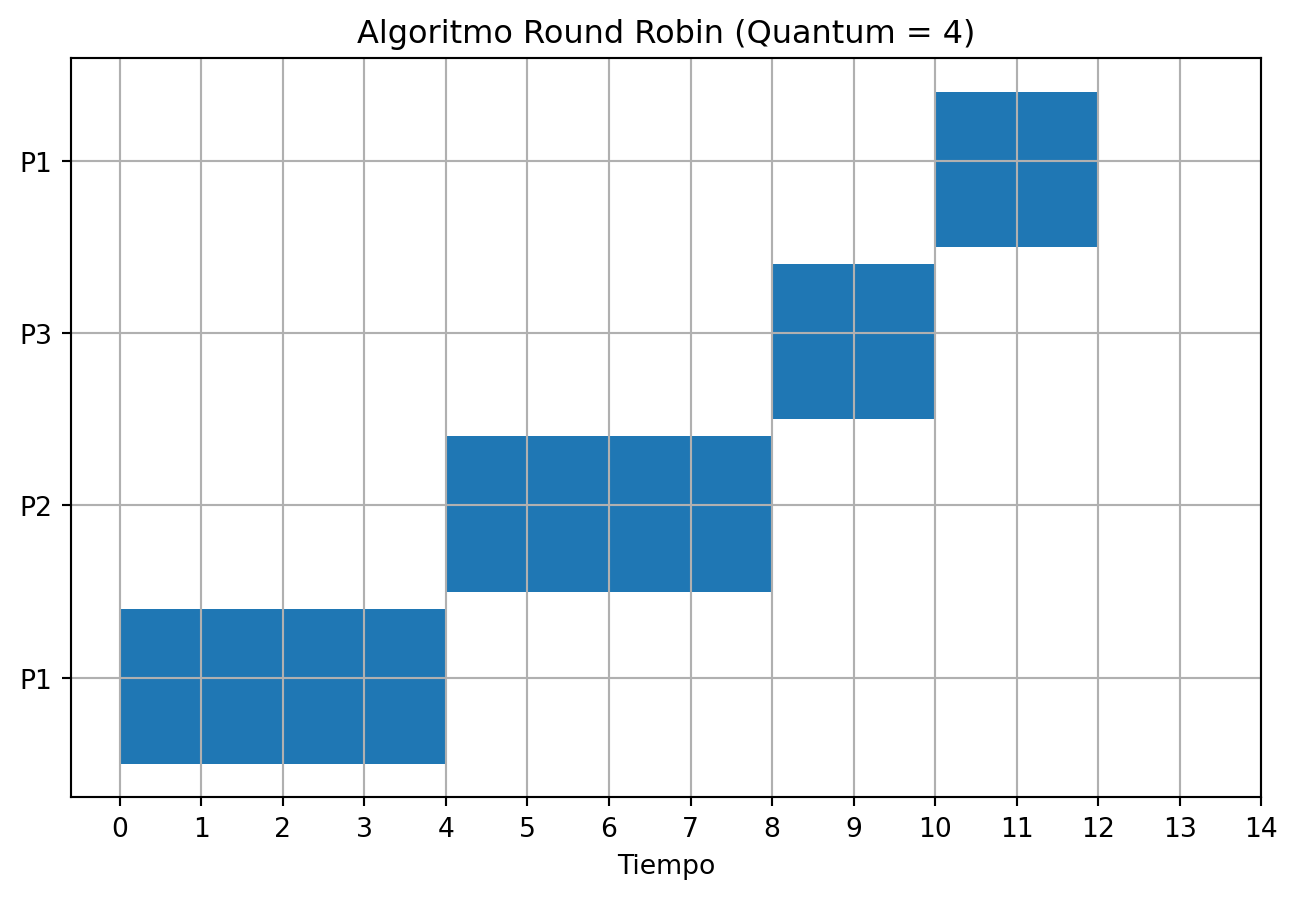
Ejemplo de Round Robin
Supongamos 3 procesos P1, P2, P3 que llegan y un deben ser atendidos con un quantum de 4 unidades de tiempo:
P1 con tamaño 8 llega en tiempo 0
P2 tiene tamaño 4 y llega en tiempo 2
P3 tiene un tamaño 2 y llega en tiempo 5
Código
import pandas as pdimport matplotlib.pyplot as pltimport numpy as np# Definir los tiempos de inicio y duración de cada proceso en cada turnotiempos_inicio = [0, 4, 8, 10, 12] # Tiempos de inicio de cada turnoduraciones = [4, 4, 2, 2, 2] # Duraciones de cada turno# Asignar procesos a los turnos de ejecución (P1 -> P2 -> P3 -> P1 -> P2 -> P3)asignacion_procesos = ['P1', 'P2', 'P3', 'P1']# Crear la figura y el gráfico de Gantt para Round Robinfig, ax = plt.subplots(figsize=(8, 5))# Crear el gráfico de Gantt para cada proceso en cada turnofor i, (proc, t_inicio, duracion) inenumerate(zip(asignacion_procesos, tiempos_inicio, duraciones)): ax.broken_barh([(t_inicio, duracion)], (i *10, 9), facecolors=('tab:blue'))# Etiquetas y formatoax.set_xlabel('Tiempo')ax.set_yticks([i *10+5for i inrange(len(asignacion_procesos))])ax.set_xticks(range(0, [sum(duraciones)][0] +max(duraciones)-3))ax.set_yticklabels(asignacion_procesos)ax.set_title('Algoritmo Round Robin (Quantum = 4)')ax.grid(True)# Mostrar el gráficoplt.show()
Figura 5.1: Comparación de tiempos de espera en FIFO
5.2.1 Algoritmo FIFO (First In First Out)
El algoritmo FIFO o FCFS (First Come First Served) es el más simple y consiste en atender los procesos en el orden en que llegan a la cola de listos. Una vez que un proceso empieza a ejecutarse, mantiene el uso de la CPU hasta que finaliza o bloquea.
Ventaja: Es sencillo de implementar y entender.
Desventaja: Puede crear largos tiempos de espera si un proceso extenso llega antes que otros muy cortos (fenómeno conocido como convoy effect).
Características de FIFO
Política no apropiativa: Una vez que el proceso comienza a ejecutarse, no se interrumpe hasta que se complete.
Los procesos se ejecutan por orden de llegada: El primer proceso en llegar, es el primero en ser atendido.
Todos los procesos esperan en una sola cola: Los procesos en la cola deben esperar su turno hasta que la CPU esté libre.
El algoritmo SJF (Shortest Job First, en español “Trabajo Más Corto Primero”) selecciona para su ejecución el proceso con el tiempo de ráfaga (tiempo de CPU requerido) más corto.
Ventaja: Minimiza el tiempo promedio de espera y, a menudo, el tiempo de retorno promedio.
Desventaja: Requiere conocer (o estimar) la duración de la ráfaga de CPU de cada proceso con anticipación, lo cual no siempre es factible.
Características del SJF:
No Apropiativo: Una vez que un proceso con la menor duración es seleccionado, se ejecuta hasta su finalización sin interrupciones.
Minimización del tiempo promedio de espera: Como se priorizan los procesos más cortos, se optimiza el tiempo promedio de espera de todos los procesos en el sistema.
Problema del “hambre”: Los procesos largos pueden quedar esperando indefinidamente si continuamente llegan procesos más cortos, lo que se conoce como starvation.
Se puede observar que el P2, con menor tiempo de ejecución es atendido primero, luego es ejecutado el P1 (ráfaga 6), y finalmente, el P3.
5.3 Algoritmo de Prioridad
El algoritmo de Prioridad es una política de planificación en la cual cada proceso se asocia con un valor de prioridad. Los procesos con mayor prioridad tienen preferencia para acceder a la CPU y se ejecutan primero. Este enfoque es útil en sistemas donde ciertos procesos requieren un tratamiento preferencial debido a su importancia o urgencia.
La prioridad puede asignarse de dos maneras:
Prioridad externa: Determinada por factores ajenos al sistema operativo, como la importancia del proceso para el usuario o la organización.
Prioridad interna: Calculada por el sistema operativo en función de parámetros como el tiempo estimado de ejecución, los recursos solicitados o el historial de uso de CPU.
Características del Algoritmo de Prioridad:
Puede ser apropiativo o no apropiativo:
En la versión no apropiativa, una vez que un proceso comienza a ejecutarse, continúa hasta terminar.
En la versión apropiativa, si llega un proceso con mayor prioridad, el proceso en ejecución se interrumpe.
Problema del “hambre”: Los procesos de baja prioridad pueden sufrir inanición si continuamente llegan procesos de mayor prioridad.
Solución al problema de inanición: Implementar el “envejecimiento” (aging), donde la prioridad de un proceso aumenta gradualmente con el tiempo de espera.
Ejemplo de Algoritmo de Prioridad (no apropiativo)
Supongamos que tenemos tres procesos con las siguientes características:
P1: Tiempo de llegada = 0, Tiempo de ejecución = 7, Prioridad = 2
P2: Tiempo de llegada = 2, Tiempo de ejecución = 4, Prioridad = 1
P3: Tiempo de llegada = 4, Tiempo de ejecución = 5, Prioridad = 3
Donde la prioridad 1 es la más alta y 3 la más baja.
En este ejemplo, aunque P1 llega primero, debe esperar a que P2 (con mayor prioridad) termine su ejecución. P3, al tener la prioridad más baja, debe esperar a que tanto P2 como P1 terminen.
En la versión apropiativa, P1 comienza su ejecución pero es interrumpido cuando llega P2 (con mayor prioridad). Una vez que P2 termina, P1 reanuda su ejecución, y finalmente se ejecuta P3.
5.4 Algoritmo High Response Ratio Next (HRN)
El algoritmo High Response Ratio Next (HRN) es una política de planificación que prioriza los procesos en función de la relación entre el tiempo de espera y el tiempo de ejecución. A diferencia de otros algoritmos, HRN tiene en cuenta tanto el tiempo de servicio como el tiempo de espera para determinar qué proceso debe ejecutarse a continuación.
La fórmula utilizada para calcular la prioridad en HRN es:
\[
\text{Prioridad} = \frac{\text{Tiempo de Espera} + \text{Tiempo de Servicio}}{\text{Tiempo de Servicio}}
\]
Características del Algoritmo HRN:
No apropiativo: Una vez que un proceso comienza a ejecutarse, continúa hasta completarse.
Balance entre SJF y FIFO: Combina las ventajas de ambos algoritmos, favoreciendo procesos cortos pero sin ignorar aquellos que han esperado mucho tiempo.
Prevención de inanición: A medida que un proceso espera, su relación de respuesta aumenta, incrementando su prioridad.
Requiere conocer el tiempo de servicio: Al igual que SJF, necesita una estimación del tiempo de ejecución de cada proceso.
Ejemplo de Algoritmo HRN
Supongamos que tenemos tres procesos con las siguientes características:
P1: Tiempo de llegada = 0, Tiempo de servicio = 10
P2: Tiempo de llegada = 2, Tiempo de servicio = 5
P3: Tiempo de llegada = 3, Tiempo de servicio = 2
En el tiempo t=0, solo P1 está disponible, por lo que comienza a ejecutarse. En t=10, P1 termina y calculamos las prioridades:
P2: (8 + 5) / 5 = 2.6
P3: (7 + 2) / 2 = 4.5
P3 tiene mayor prioridad, por lo que se ejecuta a continuación. En t=12, P3 termina y P2 es el único proceso restante, por lo que se ejecuta.
El algoritmo de Colas Múltiples es una política de planificación compleja que divide la cola de procesos listos en varias colas separadas, cada una gestionada con su propio algoritmo de planificación. Este enfoque permite tratar diferentes tipos de procesos de manera distinta, optimizando el rendimiento global del sistema.
Características del Algoritmo de Colas Múltiples:
Clasificación de procesos: Los procesos se clasifican en diferentes categorías según sus características (interactivos, por lotes, en tiempo real, etc.).
Múltiples algoritmos: Cada cola puede utilizar un algoritmo de planificación diferente (Round Robin para procesos interactivos, FIFO para procesos por lotes, etc.).
Prioridad entre colas: Generalmente existe una jerarquía entre las colas, donde las de mayor prioridad se atienden primero.
Migración entre colas: En algunas implementaciones, los procesos pueden moverse entre colas según su comportamiento o tiempo de ejecución.
Tipos de Colas Múltiples:
Colas Múltiples sin Realimentación:
Los procesos permanecen en la misma cola durante toda su vida.
La asignación a una cola específica se realiza al crear el proceso.
No hay movilidad entre colas.
Colas Múltiples con Realimentación (Feedback):
Los procesos pueden moverse entre colas según su comportamiento.
Típicamente, los procesos nuevos entran en la cola de mayor prioridad.
Si un proceso consume demasiado tiempo de CPU, puede descender a colas de menor prioridad.
Los procesos que esperan mucho tiempo pueden ascender a colas de mayor prioridad.
Ejemplo de Colas Múltiples con Realimentación
Supongamos un sistema con tres colas:
Cola 1: Procesos interactivos (Round Robin con quantum = 2)
Cola 2: Procesos de sistema (Round Robin con quantum = 4)
Cola 3: Procesos por lotes (FIFO)
La prioridad es descendente: Cola 1 > Cola 2 > Cola 3.
graph TD
A[Nuevos Procesos] --> B[Cola 1: Interactivos]
B -->|Consume quantum| C[Cola 2: Sistema]
C -->|Consume quantum| D[Cola 3: Por Lotes]
D -->|Finaliza| E[Terminado]
B -->|Finaliza| E
C -->|Finaliza| E
D -->|Espera prolongada| C
C -->|Espera prolongada| B
En este sistema:
Todos los procesos nuevos entran en la Cola 1.
Si un proceso en la Cola 1 consume su quantum sin terminar, pasa a la Cola 2.
Si un proceso en la Cola 2 consume su quantum sin terminar, pasa a la Cola 3.
La CPU atiende primero todos los procesos de la Cola 1, luego los de la Cola 2, y finalmente los de la Cola 3.
Para evitar la inanición, los procesos que esperan demasiado tiempo en colas inferiores pueden ascender a colas superiores.
Este algoritmo es muy flexible y permite ajustar el comportamiento del sistema según las necesidades específicas, balanceando la atención entre procesos interactivos (que requieren tiempos de respuesta cortos) y procesos por lotes (que buscan maximizar el throughput).